近期,谷歌DeepMind与谷歌Quantum AI组成的研究团队基于人工智能开发了一种名为AlphaQubit的量子纠错解码器。在谷歌“悬铃木”量子处理器的真实数据处理中,该解码器对码距为3以及5的表面码解码性能优于其他最先进的解码器,并且通过数值模拟显示,在码距高达11时仍能保持优势。该研究展示了机器学习应用于量子技术中的强大潜力,为开发大规模容错量子计算机开辟了新的研究途径。该成果于11月20日发表在《自然》杂志上。

© Nature 研究论文以《用于量子处理器的高精度错误解码的机器学习(Learning high-accuracy error decoding for quantum processors)》为题发表于《自然》杂志
量子处理器容易受到环境和其他来源的噪声干扰而产生错误,常用的对策是利用冗余备份将信息编码在逻辑量子比特中来纠正物理量子比特的错误。实现量子纠错的一个关键挑战是如何解码错误,即通过检测定位到每一个物理比特究竟发生了什么错误。此前,人们设计的诸如最小权重完美匹配等算法对某些类型错误的解码是有效的,但随着量子比特数量的增加,噪声的影响变得更加复杂,传统的方法往往会遇到困难。
研究团队开发的AlphaQubit是一种使用机器学习来解决量子错误纠正问题的量子纠错解码器,其方式与人类主导的方法有根本不同。AlphaQubit不依赖于错误发生的预定义模型,而是使用数据直接从量子系统中学习,适应现实环境中复杂且不可预测的噪声。通过使用机器学习,AlphaQubit可以识别传统方法可能忽略的错误模式与关联,使其成为比现有方法更通用、更强大的解决方案。
AlphaQubit基于transformer神经网络架构,这是一种机器学习模型,已成功应用于从自然语言处理到图像识别的一系列场景中。研究团队对AlphaQubit进行了两个阶段的训练:首先是在合成数据上的训练,这使得模型能够学习量子错误的基本结构,然后是在悬铃木量子处理器真实实验数据上的训练;第二阶段使模型能够适应实际硬件中遇到的特定噪声,从而提高其整体精度。
研究团队的关键创新在于他们使用了软读出,这是一种从量子系统中提取模拟信息而不会过多干扰系统的方法。在传统的解码器中,测量读取值要么是0,要么是1,软读出则提供了关于量子比特状态的更细微的信息,这使得AlphaQubit能够对是否发生错误以及如何纠正错误做出更有依据的决定。
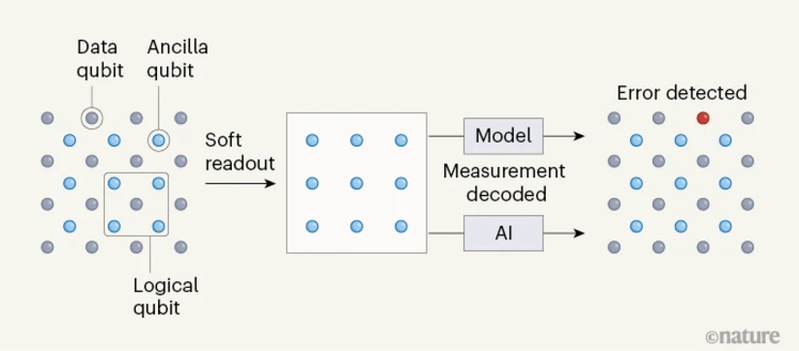
© Nature 在量子计算机中,信息被编码在逻辑量子比特里,其中包括存储数据的量子比特,以及可以测量(通过称为软读出的过程)以检测和纠正错误的辅助量子比特。然而,解码这些测量值是具有挑战性的,并且通常使用模型进行。研究团队表明人工智能驱动的解码策略可以促进量子纠错,其方式比人类设计的模型更准确,适应性更强。
在对真实数据和模拟数据进行测试时,该模型使用悬铃木处理器进行评估,并用于码距分别为3和5的表面码中的错误解码,AlphaQubit显示出比现有方法明显的优势。
研究团队通过数值模拟表明,AlphaQubit在更大的量子系统中也可以生效,在码距为11时仍能保持准确性。距离越大,每个逻辑量子比特中涉及的物理量子比特越多,纠错就越复杂。即使面对包括串扰和泄漏在内的大量噪声,AlphaQubit也优于现有的最先进方法。这一结果表明,机器学习可以比传统的人为设计算法更好地处理现实世界量子噪声的复杂性。
AlphaQubit的核心优势之一是从数据中学习的能力,使其能够适应各种类型的量子硬件。这种适应性对于仍处于早期发展阶段的量子硬件尤为重要。不同的量子处理器可能具有不同的噪声特性,而AlphaQubit通过直接从实验数据中学习,可以针对每个设备优化其性能,为纠错提供量身定制的解决方案,进而帮助量子计算机在规模和复杂性的不断增长中正确运行,缩小当今容易出错的量子设备与未来容错量子计算机之间的差距。
尽管有这些令人印象深刻的结果,逻辑错误率还需要进一步降低。理想情况下,要运行包含数千或数百万次操作的复杂量子算法,每一万亿次逻辑操作的错误不应超过一次。这需要进一步提升AlphaQubit的解码时间和正确性等性能,以满足实时量子计算的需求。
此外,AlphaQubit的成功表明,其他类型的机器学习模型也可以用于解决量子计算中的特定挑战,这包括了优化量子电路以及开发量子算法。这项研究展示了人工智能增强量子技术的力量,通过结合量子物理和机器学习,这些创新可以释放量子领域的真正潜力。
论文链接:
https://www.nature.com/articles/s41586-024-08148-8
报道链接: